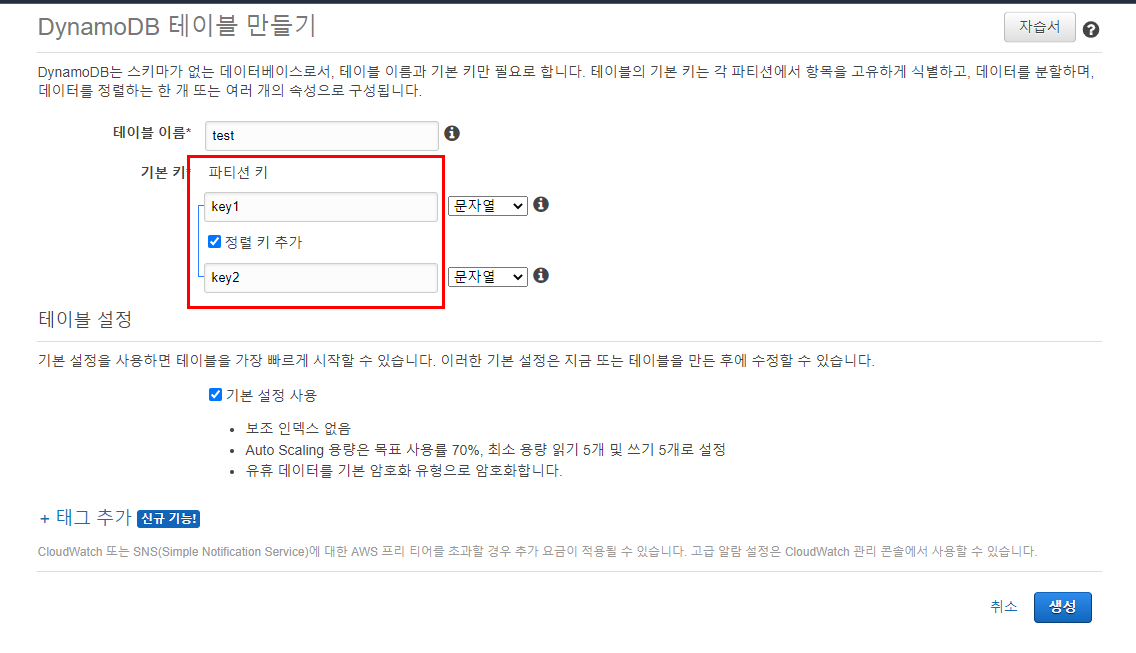
Query Hash, Range key로 설정한 애들로 indexing 처리가 되어있기 때문에 전체 데이터를 살펴보지않고도 두 key를 이용해서 데이터를 찾을 수 있다.
Range key는 이름답게 ==이 아닌 대교비교도 가능하다. (내부적으로 Hash + Btree 로 indexing을 하고있을 것 같다)
3. GSI, LSI
테이블을 위와같이 만들면 WHERE key1=A AND key2=B 같은 쿼리는 가능하겠지만 WHERE key3=A 같은 쿼리는 불가능하다. 그럼 또 맨땅에 헤딩식인 Scan을 써야하는데 그게 싫다면 Secondary Index을 쓰면 된다. 종류는 두 가지가 있다.
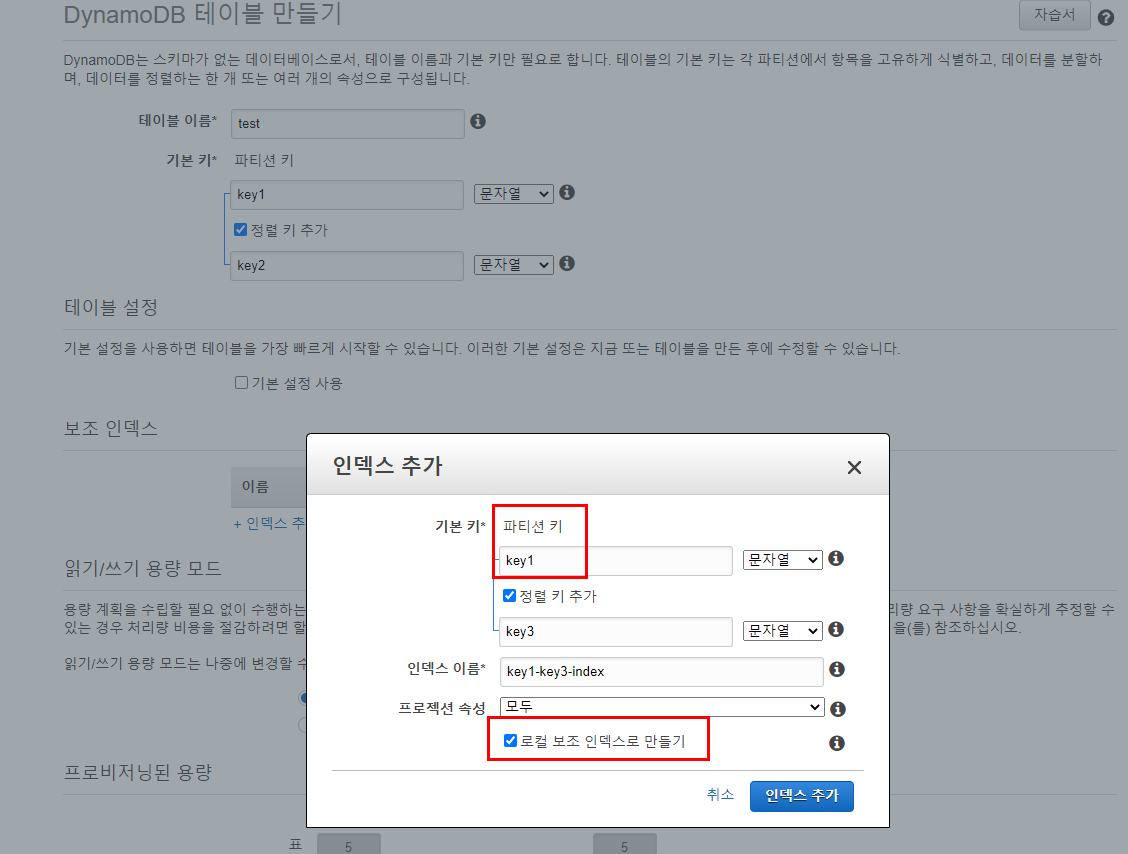
Local Secondary Index 기본 Hash Key에 *Range Key 조합을 더 두는 방식이다. 테이블을 생성할 때만 세팅이 가능하기 때문에 처음부터 잘 설계해야한다. 나중에 LSI를 추가하고싶어지면 기존 테이블을 삭제하면서 마이그레이션 하는 방법 밖에 없다.
key1 * key2 이외에도 key1 * key3 혹은 key1 * key4 로 인덱싱을 하나 더 하겠다는 뜻이다. 테이블 자체의 기본 Hash Key(key1)에 공생하는 range key를 하나 더 파서 인덱싱한다 해서 Local이라는 이름이 붙은것 같다.
보조 인덱스를 추가할때 (테이블 Hash key== 보조인덱스 Hash key) && Range key 선택 이여야만 LSI로 만들기 checkbox가 활성화 된다.
Global Secondary Index 테이블 자체의 기본 Hash Key에 공생하지 않고 새로운 Hash Key (+Range Key)를 둬서 인덱싱을 하겠다는 뜻이다. GSI는 테이블 생성 후에도 설정가능하고 추후 변경, 삭제가 가능하다. key3 key3*key4 key4*key3
위처럼 인덱싱이 가능하다. LSI에서처럼 key1*key2를 해도 상관없다. 어차피 새로운 Hash Key를 둬서 인덱싱하는 것이기 때문에 같던 말던 dynamoDB는 상관 안한다. 어? Hash key이름이 key1인데 LSI로 하고 싶으면 체크해라 아니면 그냥 GSI로 한다 ~~ 라고 체크박스를 표시해준다.
GSI를 추가하고 난 뒤 해당 key를 이용해 쿼리를 날릴 수 있게 되었다.
Secondary Index 의 Hash*Range는 고유할 필요 없다. 기본 테이블의 Hash*Range만 고유하면 된다.